Mastering Data Integrity: Unlock the Power of AWS Glue Data Quality

Before we began, let’s take a moment to understand what data quality means.
Data quality is the cornerstone of any successful data-driven organization. It ensures that the data being used is accurate, complete, and consistent, enabling reliable decision-making and efficient operations. Maintaining data quality is crucial because poor-quality data can lead to errors, inefficiencies, and inaccurate insights, which can negatively impact business performance. By prioritizing data quality, organizations can trust their data, improve processes, and make more informed decisions, ultimately driving better outcomes and achieving long-term success.
Example data-frame
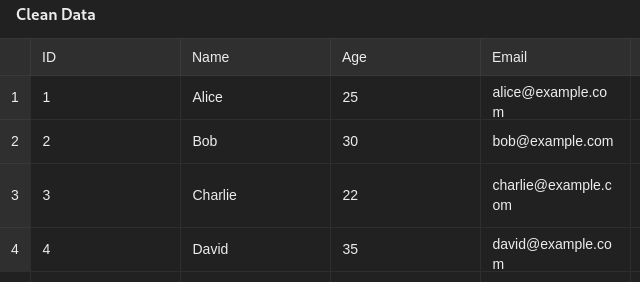
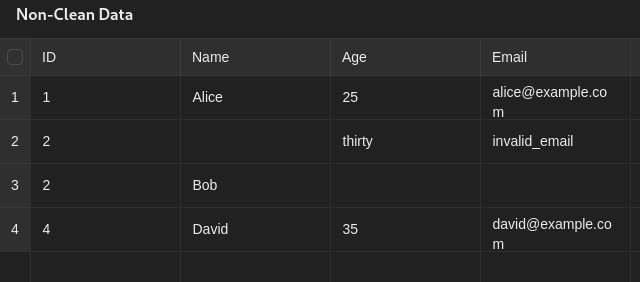
How can we identify whether the data is clean or not?
To identify whether data is clean or not, we typically look for a few key indicators:
- Missing Values: Check for any
nullor missing values in the data. Clean data should have all required fields filled, whereas non-clean data may have empty or missing entries.
- Duplicate Entries: Check for duplicate rows or values. Clean data should not have duplicate records unless it's valid for the use case.
- Data Type Consistency: Ensure that each column contains consistent data types. For example, a column representing age should only contain numeric values, while an email field should follow a valid email format.
- Outliers and Invalid Values: Look for any abnormal or out-of-range values that may indicate errors. For example, negative ages or invalid email formats.
- Spelling and Formatting Errors: Non-clean data may contain spelling mistakes, inconsistent formatting (e.g., date formats), or incorrect capitalization.
- Data Completeness: Ensure that the dataset has all the necessary columns or attributes needed for analysis or processing.
This can be done manually using SQL for databases or Athena SQL for tables in the Glue Data Catalog. In this blog, we will focus on how to work with tables in AWS Glue Data Catalog.
Introduction to AWS Glue Data Quality
AWS Glue Data Quality introduces a feature designed to handle data quality checks. It’s built on the DeeQu framework and offers a fully managed, serverless experience. You use a special language called Data Quality Definition Language (DQDL) to set rules for checking data quality. If you're not familiar with DQDL, that's okay for now, as AWS provides an interactive GUI that helps you generate DQDL rules based on your selections. We will take a closer look at this in a moment.
Screenshot of Rule:
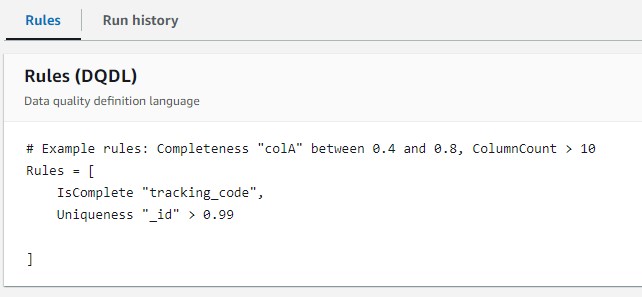
Creating a new data quality rule
Let’s talk about creating a new data quality rule in AWS Glue. A rule-set is simply a group of data quality rules used to evaluate your data. Using the AWS Glue console, you can easily create custom rule-sets with Data Quality Definition Language (DQDL).
Here’s how to create one:
- In the AWS Glue console, go to Data Catalog, choose Databases, then select Tables. Pick the table you want to evaluate, such as the "tickets" table.
- Go to the Data quality tab, and in the Rulesets section, select Create ruleset. The DQDL editor will open, allowing you to start adding rules. You can write these rules directly or use the DQDL rule builder for assistance.
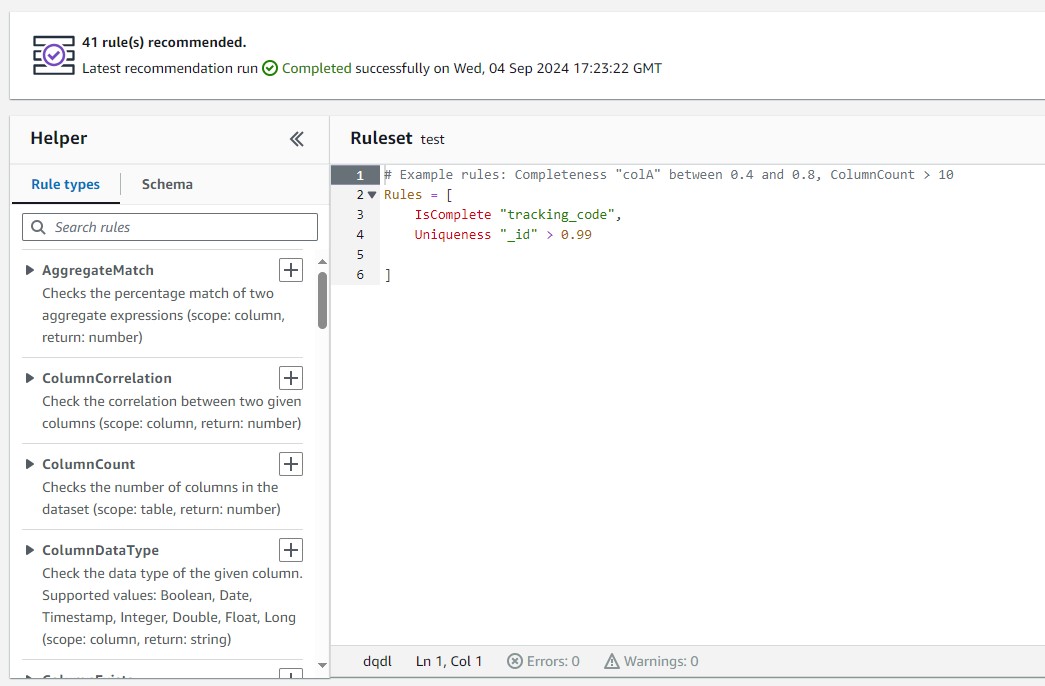
The image shows two data quality rules written in a Data Quality Definition Language (DQDL) format:
- IsComplete "tracking_code":
- This rule ensures that the column
tracking_codehas no missing or null values. In other words, every record in this column must be complete.
- This rule ensures that the column
- Uniqueness "_id" > 0.99:
- This rule checks the uniqueness of the
_idcolumn, ensuring that more than 99% of the values in this column are unique. It allows for a very small percentage of duplicates but aims for high uniqueness overall.
- This rule checks the uniqueness of the
These rules are part of a larger ruleset designed to evaluate the quality of a dataset by ensuring completeness and uniqueness in the specified columns.
- IsComplete "tracking_code":
- If you use the DQDL rule builder, you can select a rule type, add it with a plus sign, and adjust the column names and expressions as needed. For example, you could add rules to check if the "ticket_number" is complete, unique, or greater than a certain value.
- After writing your rules, give your rule-set a name and click Save.
Once your rule-set is ready, you can run it to evaluate your data quality. AWS Glue will calculate a data quality score that shows the percentage of rules that passed. In the Data quality tab, select the rule-set and choose Run. You can also configure settings like IAM roles and choose whether to publish metrics to CloudWatch or save results to S3.
The Data quality snapshot provides an overview of your recent runs. You can track your data quality score over time and see which rules passed or failed in each evaluation. By expanding the rule-set, you can dive into the details of rule failures and success rates.
Benefits and key features
Benefits and key features of AWS Glue Data Quality include:
- Serverless – There is no installation, patching or maintenance.
- Get started quickly – AWS Glue Data Quality quickly analyzes your data and creates data quality rules for you. You can get started with two clicks: “Create Data Quality Rules → Recommend rules”.
- Detect data quality issues – Use machine learning (ML) to detect anomalies and hard-to-detect data quality issues.
- Improvise your rules – with 25+ out-of-the-box DQ rules to start from, you can create rules that suit your specific needs.
- Evaluate quality and make confident business decisions – Once you evaluate the rules, you get a Data Quality score that provides an overview of the health of your data. Use Data Quality score to make confident business decisions.
- Zero in on bad data – AWS Glue Data Quality helps you identify the exact records that caused your quality scores to go down. Easily identify them, quarantine and fix them.
- Pay as you go – There are no annual licenses you need to use AWS Glue Data Quality.
- No lock-in – AWS Glue Data Quality is built on open source DeeQu, allowing you to keep the rules you are authoring in an open language.
- Data quality checks – You can enforce data quality checks on Data Catalog and AWS Glue ETL pipelines allowing you to manage data quality at rest and in transit.
- ML-based data quality detection – Use machine learning (ML) to detect anomalies and hard-to-detect data quality issues.
- Open language to express rules – ensures that data quality rules are authored consistently and simply. Business users can easily express data quality rules in a straightforward language that they can understand. For engineers, this language provides the flexibility to generate code, implement consistent version control, and automate deployments.
Summarizing the terminology
This table outlines key terms and concepts to help you understand AWS Glue Data Quality.
| Term | Definition |
| Data Quality Definition Language (DQDL) | A domain-specific language used to write AWS Glue Data Quality rules. For more information, see the DQDL reference guide. |
| Data Quality | Describes how well a dataset serves its purpose. AWS Glue Data Quality measures data quality by evaluating rules that check characteristics like freshness or integrity. |
| Data Quality Score | The percentage of data quality rules that pass (return true) when a ruleset is evaluated with AWS Glue Data Quality. |
| Rule | A DQDL expression that checks a specific characteristic of your data and returns a Boolean value (true or false). |
| Analyzer | A DQDL expression that gathers data statistics. It helps detect anomalies and hard-to-spot data quality issues over time using machine learning algorithms. |
| Ruleset | A collection of data quality rules associated with a table in AWS Glue Data Catalog. Each ruleset is assigned an Amazon Resource Name (ARN) when saved. |
| Observation | An unconfirmed insight generated by AWS Glue after analyzing data statistics from rules and analyzers over time. |
To wrap things up, AWS Glue Data Quality gives you an easy and effective way to keep your data in check. With DQDL, you can create tailored rulesets to evaluate your data and get a clear data quality score. Plus, with analyzers and observations, it helps uncover any hidden issues, ensuring your data stays reliable and ready for action. It’s a solid tool to have when you want to make sure your data is always up to standard!
Author : Divyansh Patel